Lucas Nussbaum: Giving up on Ruby packaging
 I have finally reached a decision regarding my involvement in the Debian Ruby packaging efforts. I have decided to stop. This has been a very hard decision to make. I have invested huge amounts of time in that work over the years. I still love the language, and will continue to use it on a daily basis for my own developments. I still hope that it will succeed. I know that some people will be disappointed by that decision (and that others will think your work was useless anyway, people should use RVM and rubygems ).
But I also know that I won t be able to push for all the required changes alone. I just don t have the time, nor the motivation. For the record, here are the changes I would have liked to see in the Ruby community.
The core Ruby development community should mature.
I have finally reached a decision regarding my involvement in the Debian Ruby packaging efforts. I have decided to stop. This has been a very hard decision to make. I have invested huge amounts of time in that work over the years. I still love the language, and will continue to use it on a daily basis for my own developments. I still hope that it will succeed. I know that some people will be disappointed by that decision (and that others will think your work was useless anyway, people should use RVM and rubygems ).
But I also know that I won t be able to push for all the required changes alone. I just don t have the time, nor the motivation. For the record, here are the changes I would have liked to see in the Ruby community.
The core Ruby development community should mature.The core Ruby development community is still dominated by Japanese developers. While not a bad thing in itself, it is easily explained by the fact that the main development mailing list, where most of the important decisions are taken, is in japanese. ruby-dev@ should be closed, and all the technical discussions should happen on the english-speaking ruby-core@ list instead. The release management process should also improve. Currently, it looks like a total mess. The following Ruby development branches are actively maintained:
ruby_1_8 (106 commits over the last six months)
ruby_1_8_6 (4 commits over the last six months)
ruby_1_8_7 (35 commits over the last six months)
ruby_1_9_1 (4 commits over the last six months)
ruby_1_9_2 (227 commits over the last six months)
trunk (1543 commits over the last six months) While the state of the ruby_1_8_6 and ruby_1_9_1 branches is clear (very important bugfixes only), the state of all of the other branches is rather unclear.
What s the stable Ruby branch? 1.8 or 1.9? If it s 1.9, why are people still actively developing in the ruby_1_8 branch? How long will they continue to be maintained in parallel, dividing the manpower? Is a Ruby 1.8.8 release to be expected? Will it be ABI/API compatible with 1.8.7? Is the ruby_1_8_7 branch really bugfixes-only? How much testing of it has been done? If it s bugfixes-only and regression-free, I should push it to Debian squeeze, due to be released in a few weeks. But would you recommend that? Due to past breakages in the ruby_1_8_7 branch, it s unlikely that we will do it.
Is the ruby_1_9_2 a regression-free, bugfix-only branch? If yes, isn t 227 commits over 6 months a lot? What will be the version of the next release of trunk ? When is it expected? Will it be ABI-compatible with the current ruby_1_9_2 branch? API-compatible?
New releases in the 1.8.7 and 1.9.2 branches were done on december 25th. Why were they no betas or RCs allowing wider testing? How much testing has been done behind the scenes? Most of those questions have no clear answer. The Ruby development community should build a common understanding of the status of the various branches, and of their release expectations. Releasing on december 25th of each year sounds fun, but is releasing when everybody is on vacation really a good idea? It would be fantastic to have something similar to Python Enhancement Proposals in the Ruby community. But having open discussions in english about the major issues would already be great. Ruby is not just the interpreter.
The Ruby development community should clearly define what the Ruby platform is. There are some big players, like Rails, and newer interpreter releases should not be done before ensuring that those big players still work. Also, since we have alternative Ruby interpreters, like JRuby, Rubinius and MacRuby, we need a clear process on how they integrate with the rest of the ecosystem. For example, having each of them rely on their own outdated fork of the whole stdlib is ridiculous, since it s not where they compete. The Ruby community should acknowledge that RVM and Rubygems are not for everybody. People who say so should be laughed at. Of course, RVM and Rubygems are nice tools for some people. But it is completely wrong to believe that compiling from source using RVM should be the standard way of installing Ruby, or that all people interested in installing Redmine should know that Ruby has its own specific packaging system. The Ruby community should work with their target platforms to improve how Ruby is distributed instead of reinventing the wheel. That includes Debian, but also RedHat-based distros, for example. It is likely that it won t be possible to reach a one-size-fits-all situation. But that s real life. Some people in the Ruby community should stop behaving like assholes. As one of the Debian Ruby maintainers, I have been routinely accused of creating crippled packages on purpose (FTR, I don t think that the Debian packages are crippled, despite what the rumors says). Debian is not the only target of that. Just yesterday, someone called for abandonning YARV (the new Ruby VM in Ruby 1.9), calling it Yet Another Random Vailure. This kind of comments is really hurting the people who are investing their free time in Ruby, and is turning away people who consider getting involved. In Debian, we have had a lot of problems getting people to help with Ruby maintenance since they are getting shit from the community all the time. So, what s the future for Ruby in Debian?
- For the interpreter, the two other maintainers, Akira Yamada and Daigo Moriwaki, are of course free to continue their work, and I wish them good luck.
- For the pkg-ruby-extras team, which maintains most of the Ruby libraries and applications, the future is less clear. The team was already badly understaffed, and I feel that I should probably clean up its status by orphaning/removing the packages that are unmaintained otherwise. This won t affect all the packages that the team maintains: some packages (like redmine) are actively maintained, and will stay.
- For me, it just means I will have more time for other things (possibly not Free Software-related). If things improve dramatically, I might also come back to Ruby packaging at some point.
Update 2: First, thanks a lot for all the interesting comments. I will make some follow-up posts trying to summarize what was said. It seems that this post also triggered some reactions on ruby-core@, with Charles Olivier explaining the JRuby stdlib fork, and Yui Naruse clarifying that all questions are welcomed on ruby-core@. This is great, really.
 So you have
So you have  our reluctant hackers get it right:
our reluctant hackers get it right:
 The final solution looked like this:
The final solution looked like this:

 This might seem like overkill, but after a nice nice 4 hour movies and series marathon, we can safely say it was totally worth it (but no, we didn t stand 4 hours of Stargate; even geeks have their limits).
Just in case the Instructables page gets hosed at some point, here s
This might seem like overkill, but after a nice nice 4 hour movies and series marathon, we can safely say it was totally worth it (but no, we didn t stand 4 hours of Stargate; even geeks have their limits).
Just in case the Instructables page gets hosed at some point, here s  This might save someone a good deal of sifting through ancient posts on
obscure forums: if you wonder why your SunBlade 1000 workstation refuses
to boot off a freshly burned DVD, keep in mind that the standard-issue DVD
drive in those machines (typically Toshiba SD-M1401) is pretty picky about
the DVD media type used. Trying to boot off DVD-R discs invariably failed
for me with a "read failed" error, while the same image burned onto a DVD+R
blank worked like a charm.
This might save someone a good deal of sifting through ancient posts on
obscure forums: if you wonder why your SunBlade 1000 workstation refuses
to boot off a freshly burned DVD, keep in mind that the standard-issue DVD
drive in those machines (typically Toshiba SD-M1401) is pretty picky about
the DVD media type used. Trying to boot off DVD-R discs invariably failed
for me with a "read failed" error, while the same image burned onto a DVD+R
blank worked like a charm.

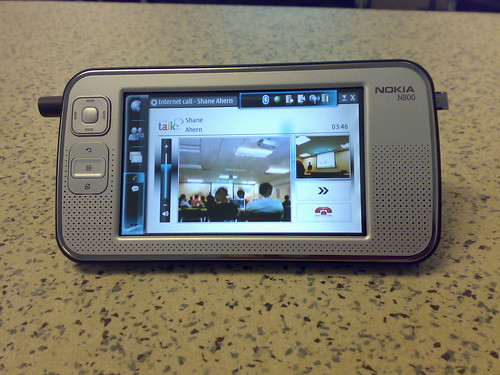
 So, I spent an hour or two this afternoon following the iPhone 4 liveblog.
It all looked fairly compelling (the screen!), right up until Steve's 'and
one more thing': video calling.
So, I spent an hour or two this afternoon following the iPhone 4 liveblog.
It all looked fairly compelling (the screen!), right up until Steve's 'and
one more thing': video calling.
 I m working for a customer who s using IBM blades. Remote access isn t limited to e.g. SoL but also possible through a Remote Console feature using a Java applet.
After migrating one of my 32bit systems to a fresh 64bit system I suddenly couldn t use this Remote Console feature any longer. The error message was (leaving it for search engines and help other affected users):
I m working for a customer who s using IBM blades. Remote access isn t limited to e.g. SoL but also possible through a Remote Console feature using a Java applet.
After migrating one of my 32bit systems to a fresh 64bit system I suddenly couldn t use this Remote Console feature any longer. The error message was (leaving it for search engines and help other affected users):
 On Wednesday, I went to a meeting of the Business Initiative for North Somerset for
On Wednesday, I went to a meeting of the Business Initiative for North Somerset for 
 So. I m trying to get familiar with libvirt and friends. To this end, I ve set up a Lucid virtual machine booting from PXE into an initrd environment which does a pivot_root to an AoE block device.
The #virt channel on irc.oftc.net told me that in order to have libvirt provide PXE capability, I would have to install a recent version of libvirt. I built version 0.7.5-3 from sid on my karmic laptop and it seems to be working okay.
I decided to set up the pxe root directoy in /var/lib/tftproot just because that s what the
So. I m trying to get familiar with libvirt and friends. To this end, I ve set up a Lucid virtual machine booting from PXE into an initrd environment which does a pivot_root to an AoE block device.
The #virt channel on irc.oftc.net told me that in order to have libvirt provide PXE capability, I would have to install a recent version of libvirt. I built version 0.7.5-3 from sid on my karmic laptop and it seems to be working okay.
I decided to set up the pxe root directoy in /var/lib/tftproot just because that s what the 
 I'm a notoriously late adopter of new technologies. Sure, if I
think that something is potentially a good idea, I'll go for it,
but for the most part, I assume that things are stupid. I refused
to use the WWW for many years, thinking it was idiotic. Now I use
the WWW. I find microblogging to be inane and narcissistic at best,
but I have derived mild amusement from Shaq on Twitter. Microsoft
Windows is something I thought would be ridiculously unsuccessful,
because it didn't do anything I would find useful.
The list goes on and on, and includes something known in the popular
vernacular as configuration management . I've been hearing about
BladeLogic and Opsware for quite some time, and idly wondering who
the incompetent fools are that need something like this. Back in
my day we could manage 100 servers with relative ease; no centralized
authentication (because it was a running argument about whether
NIS sucked more than NIS+ or vice-versa), no cfengine, no prebuilt
server images or any of that jazz. If, for some reason, we needed
to make the same change to all servers at once, or some subset thereof,
we would just script it.
So when one of my acquaintances started raving about Puppet, I
assumed it was equally pointless. We'll call him Downs.
Downs exhibits a pattern of behavior where he will rave about
something for a few weeks, sometimes without having even tried
it first, and then eventually become disillusioned with it and
start ranting with the same fervor with which he had insisted
that whatever fad of the week was the greatest thing ever.
It came as no surprise to me when he fell out of love with
Puppet and started raving about how much better Chef is.
In case you're wondering, he still has not tried Chef to
this day.
Finally someone convinced me of the value of Puppet. I do not
think it is the Way and the Light, but I do see a few situations
wherein it makes sense to sacrifice efficiency, flexibility,
sanity, and system resources to gain a way of building a
near-identical machine from scratch. Now, beyond the flaws
inherent to a solution like this, Puppet does have some annoying
flaws which I find unnecessary, and which Downs ranted about back
when I had absolutely no idea what he was talking about.
I disregarded his alleged preference for Chef, but I have heard
intelligent people extoll the virtues of Chef, and to a lesser
extent Bcfg2. So I took a very brief look at each of those, and
was pretty much horrified by what I found.
If I need something Puppet-like in the very near future, I will
probably be choosing Puppet. I have no intention of running
Puppet on machines I manage all by myself though.
For that eventuality I am NIHing something with what I consider
a better design. The current code is published, but it does
not do very much, and requires linking with libdpkg.a which does
not exist in any package (but Guillem's working on that, I think).
I have no idea whether or not I'll have the motivation to finish
it all by myself, but it is Free Software.
This post is intentionally weak on details, or deets as the
kids call them.
I'm a notoriously late adopter of new technologies. Sure, if I
think that something is potentially a good idea, I'll go for it,
but for the most part, I assume that things are stupid. I refused
to use the WWW for many years, thinking it was idiotic. Now I use
the WWW. I find microblogging to be inane and narcissistic at best,
but I have derived mild amusement from Shaq on Twitter. Microsoft
Windows is something I thought would be ridiculously unsuccessful,
because it didn't do anything I would find useful.
The list goes on and on, and includes something known in the popular
vernacular as configuration management . I've been hearing about
BladeLogic and Opsware for quite some time, and idly wondering who
the incompetent fools are that need something like this. Back in
my day we could manage 100 servers with relative ease; no centralized
authentication (because it was a running argument about whether
NIS sucked more than NIS+ or vice-versa), no cfengine, no prebuilt
server images or any of that jazz. If, for some reason, we needed
to make the same change to all servers at once, or some subset thereof,
we would just script it.
So when one of my acquaintances started raving about Puppet, I
assumed it was equally pointless. We'll call him Downs.
Downs exhibits a pattern of behavior where he will rave about
something for a few weeks, sometimes without having even tried
it first, and then eventually become disillusioned with it and
start ranting with the same fervor with which he had insisted
that whatever fad of the week was the greatest thing ever.
It came as no surprise to me when he fell out of love with
Puppet and started raving about how much better Chef is.
In case you're wondering, he still has not tried Chef to
this day.
Finally someone convinced me of the value of Puppet. I do not
think it is the Way and the Light, but I do see a few situations
wherein it makes sense to sacrifice efficiency, flexibility,
sanity, and system resources to gain a way of building a
near-identical machine from scratch. Now, beyond the flaws
inherent to a solution like this, Puppet does have some annoying
flaws which I find unnecessary, and which Downs ranted about back
when I had absolutely no idea what he was talking about.
I disregarded his alleged preference for Chef, but I have heard
intelligent people extoll the virtues of Chef, and to a lesser
extent Bcfg2. So I took a very brief look at each of those, and
was pretty much horrified by what I found.
If I need something Puppet-like in the very near future, I will
probably be choosing Puppet. I have no intention of running
Puppet on machines I manage all by myself though.
For that eventuality I am NIHing something with what I consider
a better design. The current code is published, but it does
not do very much, and requires linking with libdpkg.a which does
not exist in any package (but Guillem's working on that, I think).
I have no idea whether or not I'll have the motivation to finish
it all by myself, but it is Free Software.
This post is intentionally weak on details, or deets as the
kids call them.
 Just wanted to share comments on some movies I've watched recently.
Just wanted to share comments on some movies I've watched recently.
 Recently I posted a brief tool for managing "dotfile collections". This tool was the rationalisation of a couple of adhoc scripts I already used, and was a quick hack written in nasty bash.
I've updated my tool so that it is coded in slightly less nasty Perl. You can find the
Recently I posted a brief tool for managing "dotfile collections". This tool was the rationalisation of a couple of adhoc scripts I already used, and was a quick hack written in nasty bash.
I've updated my tool so that it is coded in slightly less nasty Perl. You can find the  Modern daemon implementations can be run in a variety of ways, in a range of contexts. The daemon software itself can be a useful tool in environments where the associated traditional system service is neither needed nor desired. Unfortunately, common debian packaging practice has a tendency to conflate the two ideas, leading to some potentially nasty problems where only the tool itself is needed, but the system service is set up anyway. How would i fix it? i'd suggest that we make a distinction between packages that provide tools and packages that provide system services. A package that provides the system service foo would need to depend on a package that provides the tool foo. But the tool foo should be available through the package manager without setting up a system service automatically. Bad Examples Here are some examples of this class of problem i've seen recently:
Modern daemon implementations can be run in a variety of ways, in a range of contexts. The daemon software itself can be a useful tool in environments where the associated traditional system service is neither needed nor desired. Unfortunately, common debian packaging practice has a tendency to conflate the two ideas, leading to some potentially nasty problems where only the tool itself is needed, but the system service is set up anyway. How would i fix it? i'd suggest that we make a distinction between packages that provide tools and packages that provide system services. A package that provides the system service foo would need to depend on a package that provides the tool foo. But the tool foo should be available through the package manager without setting up a system service automatically. Bad Examples Here are some examples of this class of problem i've seen recently:  Some spring days just seem full to bursting with unusual experiences. I spent
the night at the
Some spring days just seem full to bursting with unusual experiences. I spent
the night at the 
{kind=link}